起因
这几天在做云途单片机的CAN接口移植,学习了CAN通信,还看了一些通信时用到的环形队列、通信协议栈。
参考资料
本文搬运自 CAN通信讲解 ,自己复习使用
s32k144、云途ME0单片机参考手册
背景介绍
CAN是控制器局域网络(Controller Area Network, CAN)的简称,是一种能够实现分布式实时控制的串行通信网络。
CAN的发展历史节点:
- 1983年,BOSCH开始着手开发CAN总线;
- 1986年,在SAE会议上,CAN总线正式发布;
- 1987年,Intel和Philips推出第一款CAN控制器芯片;
- 1991年,奔驰 500E 是世界上第一款基于CAN总线系统的量产车型;
- 1991年,Bosch发布CAN 2.0标准,分 CAN 2.0A (11位标识符)和 CAN 2.0B (29位标识符);
- 1993年,ISO发布CAN总线标准(ISO 11898),随后该标准主要有三部分:
- ISO 11898-1:数据链路层协议
- ISO 11898-2:高速CAN总线物理层协议,通信速度为 125kbps-1Mbps。
- ISO 11898-3:(整合了ISO11519)低速CAN总线物理层协议,通信速度为 125kbps 以下。
- 2011年,开始CAN FD协议的开发。
- 2015年ISO11898-1进行了修订,将CAN FD加入其中。
CAN总线协议介绍
CAN总线协议有CAN1.0、CAN2.0(CAN2.0A、CAN2.0B),其中CAN2.0对比1.0,主要是增加了CAN的扩展帧定义。现在我们所说的CAN通常都是指CAN2.0标准的总线。
CAN-FD协议在原有的CAN协议基础上,增加了可变波特率、扩大数据场、提升校验算法安全性等改进。
本文主要讲述CAN的数据通信,CAN-FD的区别会在其他文章单独讲解。
CAN的物理通信形式
通过两条通信线(双绞线)产生的电压差传输数据,一个CAN网络里的所有节点都挂在这两条通信线上,使用差分信号半双工通信。
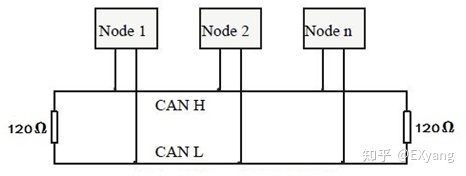
CAN 使用称为 CANH / CANL 的通信线路执行传输和接收。没有电位差的信号称为隐性(Recessive)信号,其逻辑值为1。具有电位差的信号称为显性(Dominant)信号,其逻辑值0。如果通信总线上发生显性和隐性(Recessive)冲突,则显性(Dominant)优先。总线空闲时保持隐性。
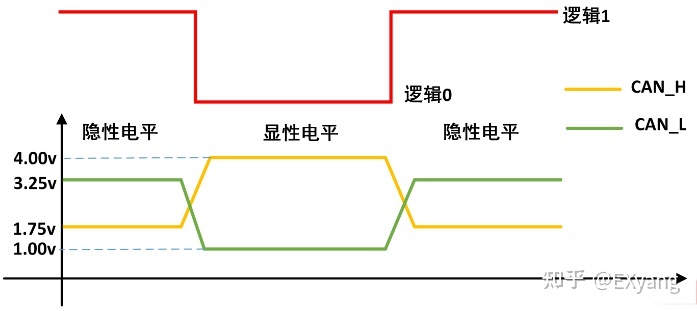
CAN总线的物理层逻辑电平,分为高速ISO11898标准(125kbps ~ 1Mbps)和低速ISO11519标准(10kbps ~ 125kbps);
低速的物理层电平如图:
而我们现在通常使用的CAN2.0,都是使用高速CAN标准,其物理层电平如图:
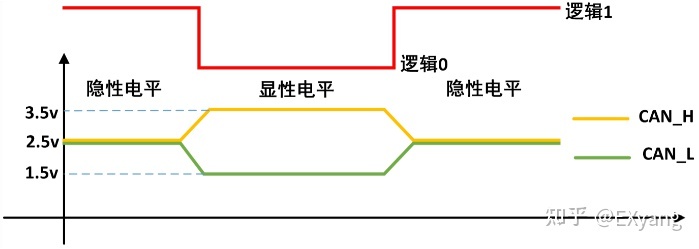
对于高速CAN,总结一下,也就是:
- CAN_H-CAN_L < 0.5V 时候为隐性的,逻辑信号表现为”逻辑1”- 高电平。
- CAN_H-CAN_L > 0.9V 时候为显性的,逻辑信号表现为”逻辑0”- 低电平。
关于CAN通信的电平传输,一个重要概念就是:
CAN总线在电平传输上,具有仲裁判断逻辑,优先级为:显性(低电平)>隐形(高电平)!
在理解CAN总线传输的整个过程中,主要就是清楚这一规则在传输时的灵活运用,并定义的各种帧形式。
CAN的数据格式
CAN的数据定义了有5种帧类型:
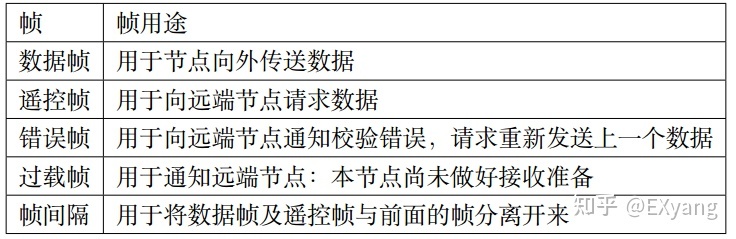
其中,遥控帧也常被称为远程帧。CAN的应用开发者只能使用“数据帧”和“遥控帧”,其他的3种帧类型是由CAN的底层固件自动帮我们在特定场景下进行收发,开发者无需担心也无法直接参与控制。
所以,本文把“数据帧”和“遥控帧”与其他的3种帧类型分别进行介绍。
数据帧与遥控帧
关于数据帧,也就是我们最常用的帧类型,用于数据的收发;也是CAN通信里最主要的内容。
而遥控帧,只是CAN网络里的某一节点发送一个遥控帧请求其他的节点反馈数据给自己,关于遥控帧其实在实际使用中,显得很鸡肋,原因有:
1、CAN通信作为一种半双工通信形式,在实际使用中的应用层通信协议往往会定义好数据的应答机制与时间间隔,节点与节点之间只要按照协议规定进行数据的收发即可。
2、遥控帧与数据帧对比,其实就是一条数据长度为0的数据帧而已,只是在帧格式里的仲裁段RTR位为隐性。那么,似乎有数据帧就足够了。
3、遥控帧的概念定义只是一个预定义,所谓的请求其他节点给自己发送数据并不是强制的,与数据帧一样完全根据应用层协议来规定其具体的使用。
综上所述,CAN里定义的遥控帧实际作用不大,而且可以用数据帧配合应用协议的定义,进行替代。所以在后来的CAN-FD中已经取消了遥控帧的定义了。
本文主要以数据帧进行介绍,并简单介绍遥控帧。
数据帧与遥控帧的数据格式
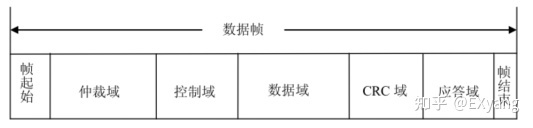
不管是Classic CAN Frame还是CANFD Frame,其帧结构都由以下7个段组成:
— SOF帧起始;
— arbitration field仲裁段;
— control field控制段;
— data field数据段;
— CRC field;
— ACK field;
— EOF.
这7个段,每个段里又都有自己的格式细分,有两种格式:标准格式和扩展格式。
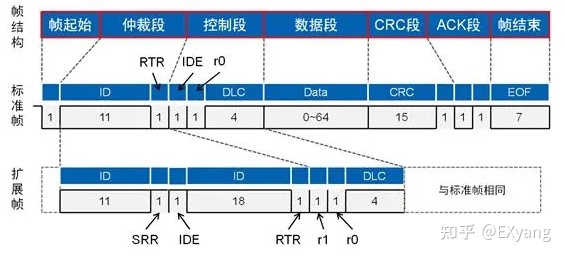
CAN的应用开发者只使用其中的仲裁段、控制段和数据段。其他部分都由CAN底层固件自动封装!
由上图可以看到,对于仲裁段和控制段在标准帧与扩展帧里有不同的定义,其他段一致。
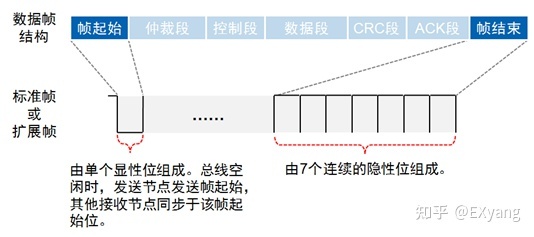
帧起始与帧结束
SOF帧起始:由一个显性位(低电平)组成,发送节点发送帧起始,其他节点同步于帧起始;
EOF帧结束:由7个隐形位(高电平)组成。
仲裁段
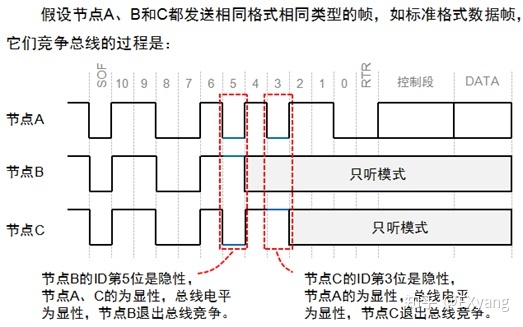
仲裁机制
只要总线空闲,总线上任何节点都可以发送报文,如果有两个或两个以上的节点开始传送报文,那么就会存在总线访问冲突的可能。但是CAN使用了标识符的逐位仲裁方法可以解决这个问题。帧ID越小,优先级越高。
CAN总线控制器在发送数据的同时监控总线电平,如果电平不同,则停止发送并做其他处理。如果该位位于仲裁段,则退出总线竞争;如果位于其他段,则产生错误事件。
仲裁段内容
RTR位:用于指示这包数据是遥控帧还是数据帧,数据帧的RTR位为显性电平,远程帧为隐性电平。
所以帧格式和帧ID相同的情况下,数据帧优先于远程帧。
IDE位:用于指示这包数据是标准帧还是扩展帧,标准帧的IDE位为显性电平,扩展帧的IDE位为隐形电平。
对于前11位ID相同的标准帧(RTR为显性的遥控帧)和扩展帧,标准帧优先级比扩展帧高。
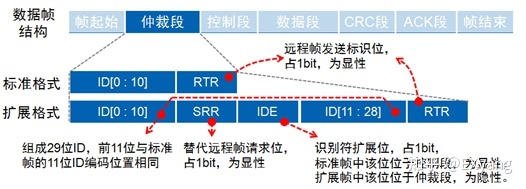
可以看到,在标准格式里,仲裁段没有IDE位,其实这个位在标准格式里是放在控制段的第一位的,这样就正好可以和扩展格式的IDE位对应上进行仲裁了。
控制段
仲裁段之后紧跟控制段,控制段共6位,标准帧的控制段由IDE、保留位r0和数据长度代码DLC组成;扩展帧控制段则由保留位r1、r0和DLC组成,如图:
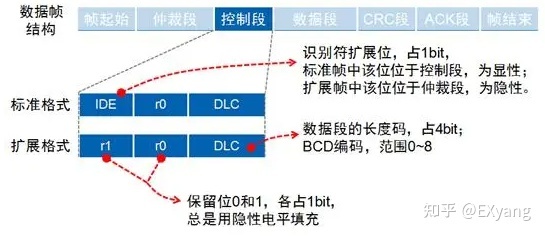
在这里可以看到,在标准格式里,IDE位放到了控制段的第一位来了,对应前文仲裁段的内容,就可以使标准格式与扩展格式进行仲裁了。
保留位( r0 、 r1 ):保留位必须全部以显性电平发送。
数据长度码( DLC ):数据的字节数必须为 0 ~ 8 字节。数据帧的DLC表示的就是当前包数据段所带的字节数,遥控帧的DLC表示的是请求返回的数据长度。
数据段
一个数据帧传输的数据量为0~8个字节。遥控帧的数据段长度固定为0。

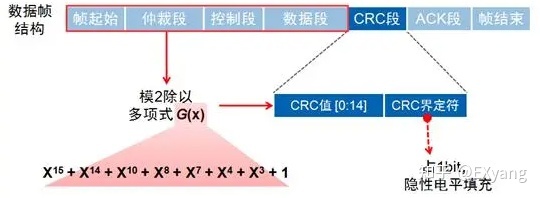
CRC段
CAN-bus使用CRC校验进行数据检错,CRC校验值存放于CRC段。 CRC校验段由15位CRC值和1位CRC界定符构成如图:
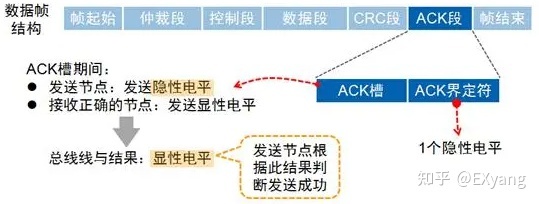
ACK段
当一个接收节点接收的帧起始到CRC段之间的内容没发生错误时,它将在ACK段发送一个显性电平如图:
位填充
CAN数据在收发上除了会遵循以上数据格式定义之外,还有一个“位填充”的底层规则(类似通信协议里的“转义符”),这个操作是在CAN的底层固件中自动判断执行的,其目的是为了增强数据正确性,以便识别错误信号。
为防止突发错误而设定,CAN协议中规定,当相同极性的电平持续五位时,则添加一个极性相反的位。填充位的添加和删除是由发送节点和接收节点完成的,CAN-BUS只负责传输,不会操纵信号。
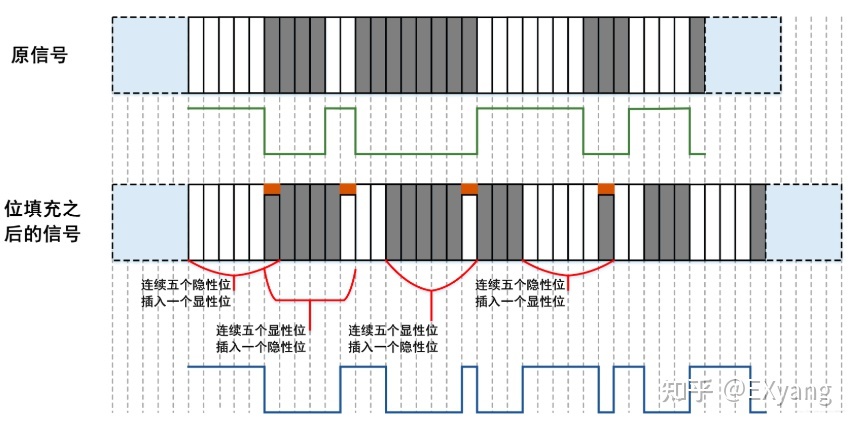
- 对于发送节点而言:
在发送数据帧和遥控帧时,对于SOF~CRC(除去CRC界定符) 之间的位流,相同极性的电平如果持续5位,那么在下一个位插入一个与之前5位反型的电平;
- 对于接收节点而言:
在接收数据帧和遥控帧时,对于SOF~CRC(除去CRC界定符)之间的位流,相同极性的电平如果持续5位,那么需要删除下一位再接收。如果这个第 6 个位的电平与前 5 位相同,将被视为错误并发送位填充错误帧。
错误帧、过载帧与帧间隔
对于这三种帧,都是在使用数据帧或遥控帧的过程当中进行错误、时序管理的辅助信号,并不会单独出现在CAN网络中;如前文所述是由CAN的底层固件自动判断并执行他们收发的,但是CAN的开发人员有必要对它们进行了解,以对CAN网络有一个整体的认识。
错误帧
尽管CAN-bus是可靠性很高的总线,但依然可能出现错误;CAN-bus的错误类型共有5种:
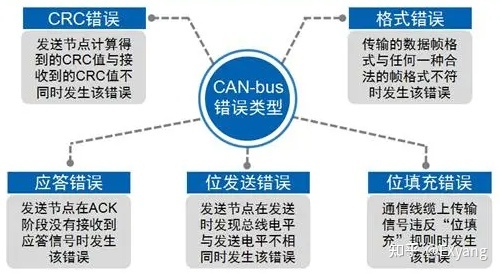
当出现5种错误类型之一时,发送或接收节点将发送错误帧。但是错误帧又有两种格式:主动错误格式和被动错误格式。
主动错误和被动错误,指的并不是发送方与接收方。而是指某一CAN节点的“错误状态”,无论发送方还是接收方,都会处于自己的错误状态,并根据自身的状态来决定自己要发送主动错误格式还是被动错误格式:
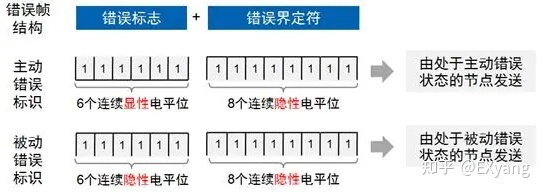
由上图可知,6个连续的显性或隐性电平位,正好违反了之前所提及的“位填充”规则,CAN总线设计上就是利用了自己的这一规则对错误数据进行刻意的覆盖破坏,使总线上其他节点都知道错误的发生。
错误状态
在CAN节点内,有两个计数器:发送错误计数器(TEC)和接收错误计数器(REC),当该节点检测到错误后,内部REC/TEC计数器会相应的增加,基于REC/TEC的值判定节点状态,CAN的错误状态如图:
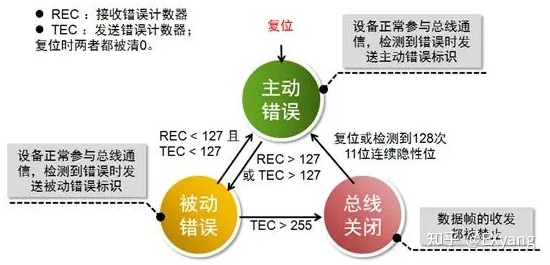
节点错误状态的转换就是一个 “量变”到“质变” 的过程:
- 主动错误状态:【REC<127 且TEC<127】
初步可判定该节点相对稳定可靠,该错误计数很可能是由于某个节点异常导致的,那么其他节点很可能也会触发该错误,那么允许该节点破坏CAN总线的异常报文并告知其他节点;
节点检测到一个错误就会发送带有主动错误标志的错误帧,因为主动错误标志是连续六个显性位,所以这个时候主动错误标志将会“覆盖”掉总线上其它节点的发送,而之前在CAN总线上传输的报文就被这“六个连续显性位”破坏掉了。
如果发出主动错误帧的节点是发送节点,这个情况下就相当于:刚刚发送的那一帧报文我发错了,现在我破坏掉它(发送主动错误帧),你们不管收到什么都不算数;
如果发出主动错误帧的节点是接收节点,这个情况就相当于:刚刚我收报文的时候发现了错误,不管你们有没有发现这个错误,我现在主动站出来告诉大家这个错误,并把这一帧报文破坏掉(发送主动错误帧),刚才你们收到的东西不管对错都不算数了。
- 被动错误状态:【REC>128 或TEC>128】
节点发送错误帧的次数较多,初步可判定该节点相对不可靠,该错误计数很可能是由于自身节点问题导致,即该错误很可能仅有该节点才有,对于其他节点而言是可以正常交互的,总线不信任该节点提供的错误标识,将不允许破坏总线数据,那么允许该节点发送错误帧“6个连续隐性位”至CAN总线,仅告知其他节点异常;
如果发出被动错误帧的节点为报文的发送节点,那么在发送被动错误帧之后,刚刚正在发送的报文被破坏,并且该节点不能在错误帧之后随着连续发送刚刚发送失败的那个报文。随之而来的是帧间隔,并且连带着8位隐性位的 “延迟传送” 段;这样总线电平就呈现出连续11位隐性位,总线上的其它节点就能判定总线处于空闲状态,就能参与总线竞争。
此时如果该节点能够竞争成功,那么它就能接着发送,如果竞争不能成功,那么就接着等待下一次竞争。这种机制的目的正是为了让其它正常节点(处于主动错误)优先使用总线。
- 总线关闭状态:【TEC>255】
一个处于被动错误状态的节点,仍然多次发送被动错误帧,使该节点转为总线关闭态;
该节点不能向总线上发送报文,也不能从总线上接收报文,整个节点脱离总线。等到检测到128次11个连续的隐性位时,TEC和REC置0,重新回到主动错误状态。
由于存在实现方式的不同,CAN总线关闭状态存在只允许用户请求恢复和检测到128个11位连续的隐性位时自恢复两种不同的恢复形式。
如果总线上只有一个节点,该节点发送数据帧后得不到应答,TEC最大只能计数到128,即这种情况下节点只会进入被动错误状态而不会进入总线关闭状态。
错误帧的发送
按照CAN协议的规定:
发生位错误、填充错误、格式错误、ACK错误时,则在错误产生的那一位的下一位开始发送错误帧。
发生CRC错误时,紧随ACK界定符后的位发送错误帧。
错误帧发送完成后,总线空闲时自动重发出错的数据帧。
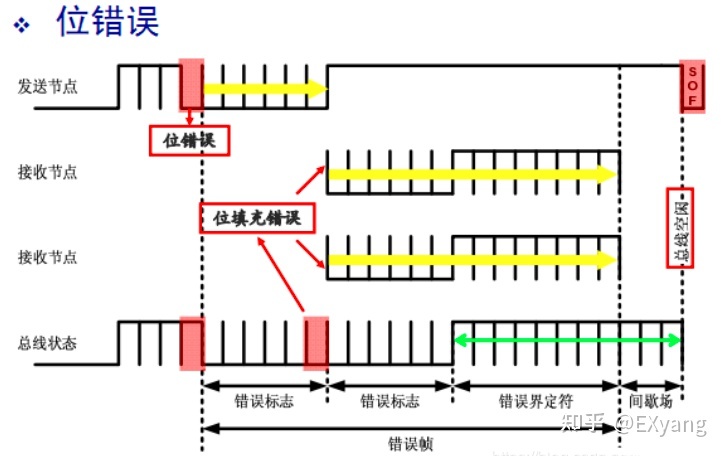
【位错误】举例(情况1):
- 设总线上所有节点处于主动错误状态;
- 当一个发送节点监控到总线上的位数值与发送的位数值不一致时,检测为位错误,并发送主动错误标志(6个连续的显性位);
- 接收节点接收到发送节点发送的6个连续的显性位时,会检测为位填充错误,也会发送主动错误标志;
- 发送节点发送完主动错误标志后,开始监控总线是否为隐性位,当总线为隐性位时,开始发送错误界定符(8个连续的隐性位);
- 当接收节点发送完主动错误标志后,开始向总线发送错误界定符; 等待错误帧发送完成,总线空闲后,发送节点重新发送出错的报文.
由于发送节点发送6个连续的显性位会破坏位填充规则,触发接收节点发送主动错误标志,发送节点和接收节点的结合是形成错误标志叠加部分的原因。
【位错误】举例(情况2):
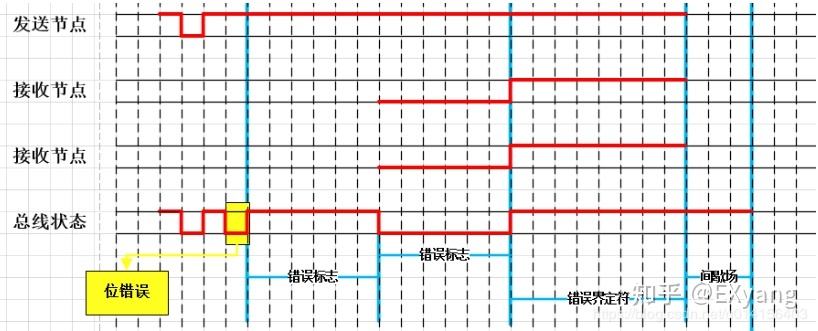
- 假设发送节点处于被动错误状态,接收节点处于主动错误状态;
- 当发送节点监控到总线上的位数值与发送的位数值不一致时,检测为位错误,并发送被动错误标志(6个连续的隐性位);
- 接收节点接收到发送节点发送的6个连续的隐性位时,会检测为位填充错误,并会发送主动错误标志;
- 发送节点发送完被动错误标志后,开始监控总线是否为隐性位,当总线为隐性位时,开始发送错误界定符(8个连续的隐性位);
- 接收节点发送完主动错误标志后,开始监控总线是否为隐性位,当总线为隐性位时,开始发送错误界定符(8个连续的隐性位);
过载帧与帧间隔
过载帧与主动错误帧非常相似,甚至可以把过载帧直接理解成也是一种错误帧,只是它的错误触发条件不同罢了。
当某个接收节点没有做好接收下一帧数据的准备时,将发送过载帧以通知发送节点;过载帧由过载标志和过载帧界定符组成,如图所示:
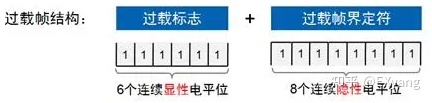
由于存在多个节点同时过载且过载帧发送有时间差问题,可能出现过载标志叠加后超过6个位的现象,如图所示:

过载帧是用于接收单元通知发送单元它尚未完成接收准备的帧。在两种情况下,节点会发送过载帧:
- 接收单元条件的制约,要求发送节点延缓下一个数据帧或远程帧的传输;
- 帧间隔(Intermission)的 3 bit 内检测到显性位
帧间隔是用于分隔数据帧、遥控帧这些有效数据的帧。数据帧和遥控帧可通过插入帧间隔将本帧与前面的任何帧(数据帧、 遥控帧、错误帧、过载帧)分开。

注意,过载帧和错误帧由于要按照发送条件立即执行,前不能插入帧间隔
CAN的采样点与波特率
根据前文描述,由于CAN总线在通信时,每个节点都会不断的监控总线上的实际电平用于仲裁、判断错误等功能,因此CAN定义了采样点这一概念指明节点对总线的监控时间点。
因为CAN要对总线上特定数据里的每一个位都要进行一次单独的监控,所以这个监控的时间点,指的是在一个“位”的时间范围之内的一个“相对时间”,比如:一个位时间的中间时刻,就把它称为50%采样点(率)。这个解释只是让读者直接理解它的大体概念,实际情况并不是这么简单。
实际的CAN采样点的位时间划分如下:
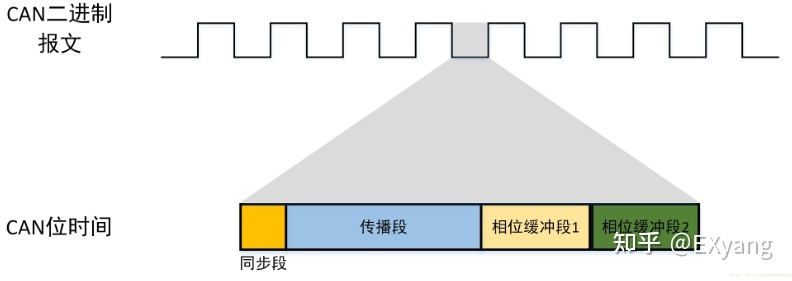
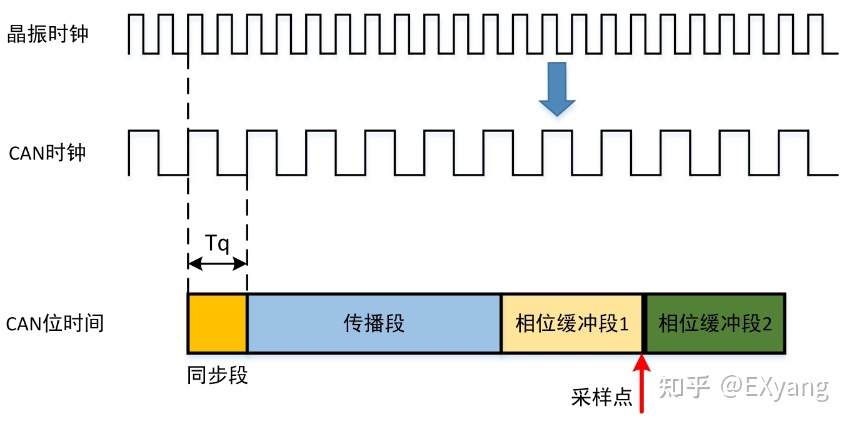
由上图可知,CAN每发送一个位,需要涉及的内容有:
时间单元(Tq):指的是CAN模块时钟提供的单位时间,与其他的芯片外设一样,任何外设模块都需要提供合适的时钟才能正常工作,在很多芯片里CAN时钟还会配合一个分频器,也就是:CAN时钟= CAN时钟源(如图中的晶振时钟) / CAN_Prescaler。时间单元指的就是分频后的实际CAN时钟的单位时间。
位时间:就是我们理解的CAN波特率里一位的时间,由上图可知,CAN每发送一个位都由几个“段”组成,而每个段又需要占用几个“时间单元(Tq)”,所以我们在使用CAN的时候,就需要通过指定这些段的Tq个数来得到CAN的波特率。
同步段(SS:Synchronization Segment):用于同步CAN总线上的各个节点。输入信号的跳变沿就发生在同步段,该段持续时间固定为 1 Tq。同步段用于同步总线上的各个节点,一个位的跳变边沿在此时间段内。
传播段(PTS:Propagation Time Segment):用于补偿各节点之间的物理传输延迟时间。传输延迟时间为信号在总线上传播时间的两倍,包括总线驱动器延迟时间。传播段的长度一般有一个取值范围,不同的控制器不完全一致,典型值为 1 – 8 TQ。在CAN-FD中取消了传播段。
相位缓冲段1(PBS1:Phase Buffer Segment 1):用于补偿节点间的晶振误差,允许通过重同步(SJW)对该段加长。在该时间段结束时进行总线电平采样点的采样。
相位缓冲段2(PBS2:Phase Buffer Segment 2):用于补偿节点间的晶振误差,允许通过重同步(SJW)对该段缩短。
不同的控制器,PBS1/PBS2 的取值范围不完全一致,一般 PS1 为 1 – 8 TQ,PS2 为 2 – 8 TQ。
在有的控制器里,把传播段与相位缓冲段1合并称为“时间段1”,而相位缓冲段2称为“时间段2”,如图:
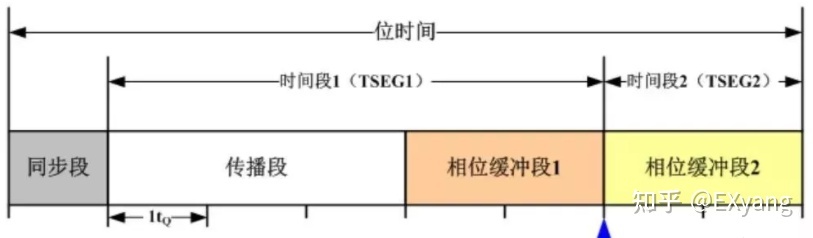
重同步(SJW):在时间段1而不是在同步段(SS)检测到有效跳变,那么相位缓冲段1(PBS1) 的时间就被延长最多SJW那么长,从而采样点被延迟了。相反如果在时间段2而不是在同步段(SS)检测到有效跳变,那么相位缓冲段2(PBS2) 的时间就被缩短最多SJW那么长,从而采样点被提前了。如图:

综上所述:
CAN时钟 = CAN时钟源 / 分频值CAN_Prescaler;
CAN波特率 = CAN时钟 / (SS(1Tq) + PTS + PBS1 + PBS2)的Tq总个数;
CAN采样点(率) = (SS(1Tq) + TSEG1) / (SS(1Tq) + TSEG1 + TSEG2) * 100%
= (SS(1Tq) + PTS + PBS1) / (SS(1Tq) + PTS + PBS1 + PBS2) * 100%;
注意:在实际的CAN使用中,一个CAN网络的各节点最好把采样点设置成一样,如果采样点的设置偏差较大,虽然可能不会造成完全不能通信的情况,但是由于不同节点的判断时间点不同,会造成CAN通信上出现较大概率的错误数据。
如果发现通信误码率较高,不妨可以排查一下各个节点的CAN采样点设置。