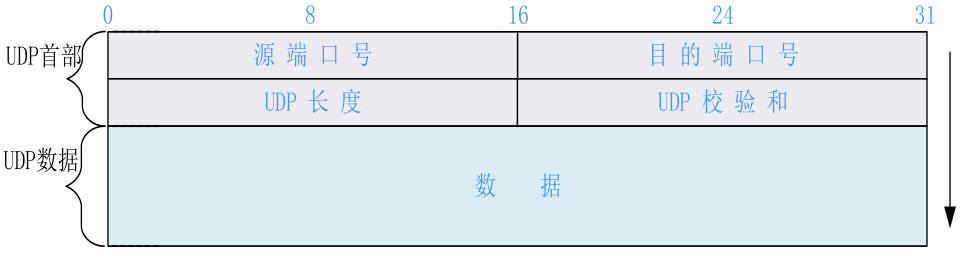
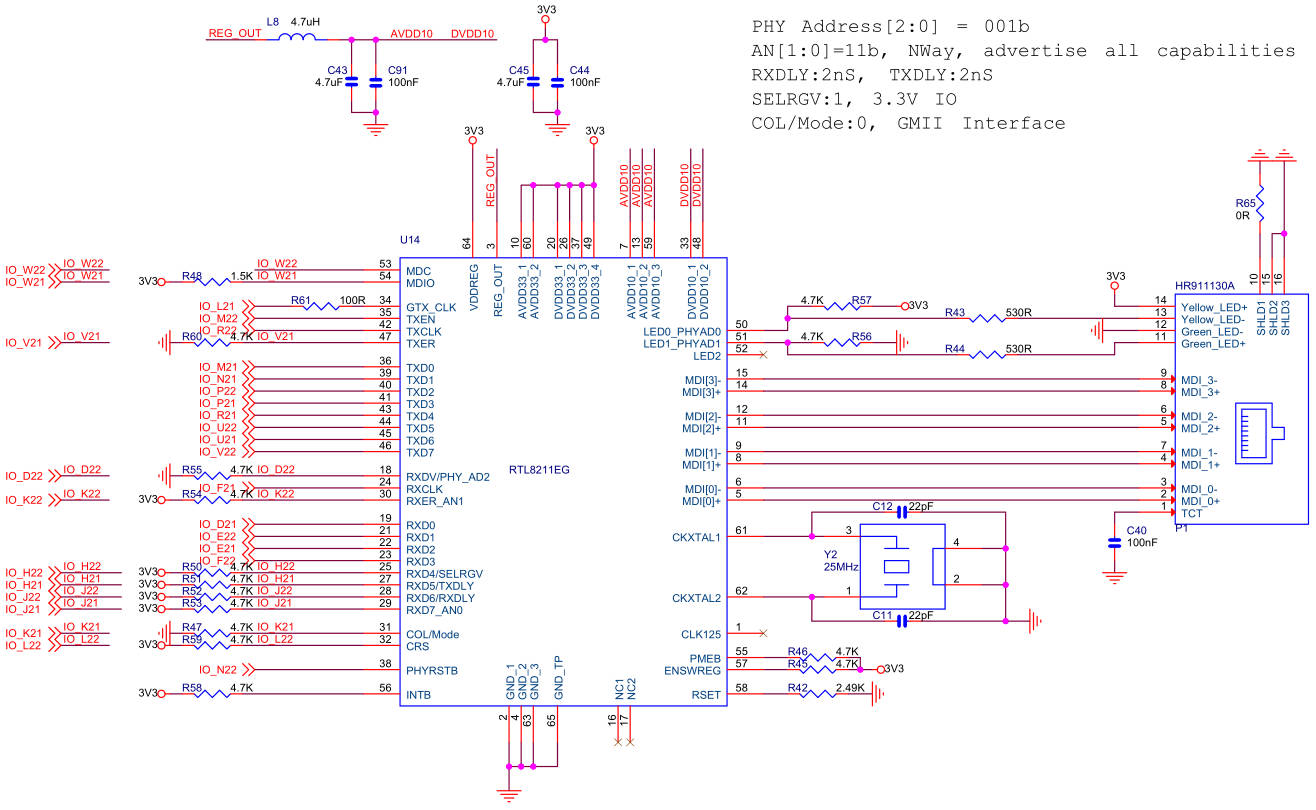
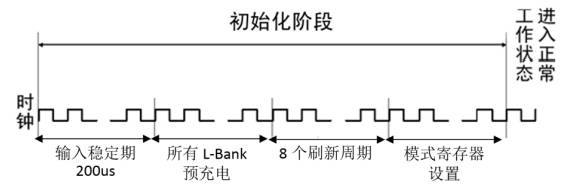
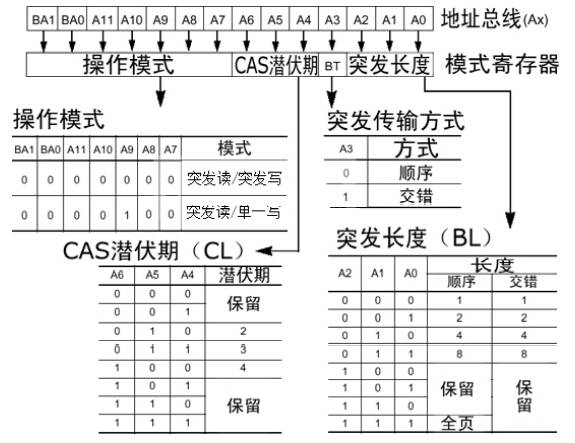
大学回忆录
大一上学期
回忆从开学前几日的寝室生活开始,室友都非常的好相处,大家在一起能玩的很嗨。再到大一我参加了两个学生会的部门(学生会办公室&党员之家实践部)和一个社团(单车俱乐部),自己在部门里认识了些不同班级不同专业的朋友,也交到了一位知心,大一上学期我天天晚上会和他去健身房,或是去钱塘江边散步,或是在寝室喝酒,元旦跨年我去了他家里,人生中第一次和别人跨年。参与了学生会的活动演出和演讲还有优秀干部的竞选;
大一寒假
寒假里我一个人坐飞机去了山东蓬莱,找我高考结束后在华为上班认识的同事,蓬莱待了7天,青岛待了2天。独自旅行,去一个陌生的地方,享受孤独,思考人生,一个人狂欢。旅行结束回家后,我学习了郭天祥的十天学会51单片机,但并没有完全学会;
大一下学期
大一下学期有我喜欢的课程模电,我通过教同学们解题来学习这门课程,因此也交到了陪伴我至今的女朋友。除了模电课我还选了一门电子课程设计也非常喜欢,老师授课讲了51单片机的知识,课程做了51数字钟(我在5月19日晚上写完,拍了个51开发版显示520倒计时的视频),最后的作业是51小车。这学期学生会部门成员积极性变差了,我最后没有选择留任执委,选择了留在电子创新实验室(一待就是三年);
大一暑假
暑假我留在实验室准备19年的全国大学生电子设计竞赛,暑假做了历年的题目(声音存储录放、风力摆、旋转倒立摆),那时候的我不知道熬夜会伤身体,每天白天调试,晚上在寝室看文档到凌晨2点。暑假里由于比较专注比赛,忘记关心女朋友,两人有过多次争执,女朋友不回消息,我直接去她家里了,就这样被她家人认识,至今我还常去她家蹭饭。这个暑假差一点点就分手了;
大二上学期
大二上学期,一开学和徐高东学长参加了工程训练大赛,那次比赛后感觉之前所有学过的东西都能联会贯通了。比赛的时候出现了意外,没有取得好成绩,东哥说了句:比赛不就是这样。随后我参加了飞思卡尔智能车竞赛,在校内训练的时候感觉都良好,本来计划我和洪晨益写程序,由于硬件画的板子实在惨不忍睹,就自己动手把硬件做完了,我那写代码的队友也很强,一人能维护好代码,那年寒假前我们俩调车调到学校关门。这学期,我和我的女朋友分手了,但几个星期又复合了,我们相互都很缺时间在一起交流;
大二寒假
那年是全世界肺炎流行的一年,寒假在家3个月,当然我也没闲着,趁家里无聊,打开电脑学了些东西,有python,tensorflow,sklearn,百度飞桨,git等,有潘利斌陪我一起学。疫情原因只能在家调飞卡,在家里把Altium Designer了一遍,画板子是没有问题了。3月在家网课,网课非常适合我,我可以不仅可以回放自己学校老师上课讲的,还能去B站慕课上找名校老师上课的视频;
大二下学期
中国疫情控制的很厉害,4月中就能返校了。这学期在学校主要是准备电赛,准备飞卡,飞卡参加的是AI组别,通过机器学习,训练后部署到单片机,实现自主规划路线;
大二暑假
暑假培训大一电赛新生,不过今年比赛延期了,暑假没有比赛。飞卡如期举行,离国赛就差0.02秒,怎么就这么可惜呀。电赛准备了很多模块,把模块间通信学的明明白白的,还有很多PCB上的设计规范也学了一遍,那年我们实验室都在看长江大学唐老师的教学视频。
大三上学期
大三上学期开始在黄道麒公司实习,老板非常厉害,抓住了疫情这个风口,做红外热像仪体温枪这些生意。公司离学校很近,我每天上完课就去公司,那段时间进步非常快,学的东西也非常多非常杂。用了好多品牌的国产mcu,用QT写了上位机,学习了二元光学。十月份浙江省电子大赛,作品实物验收满分取得了省二等奖,队友配合的非常棒!这学期上了算法与数据结构和数字逻辑设计、51汇编,非常感兴趣,买了块FPGA开发板练手;
大三寒假
寒假里我还在公司上班,老板让我住宾馆可以报销。寒假里我学习了linux应用开发,opencv,makefile,cmake,用树莓派做了个红外热像仪的demo。这个寒假我在公司借了很多书看,有linux的,opencv的,无线传感器网络的,感测技术的。在公司里和老板经常聊到很晚,我们谈未来的方向,谈生活时政等等,无所不谈,是一家有温度的公司;
大三下学期
这学期了解了一些网络安全,开关电源设计,搭建了blog,仍然在公司实习。搞的东西太杂了容易忘记自己学过什么,写写博客记录下的话翻到还能有印象。公司里主要是把之前用树莓派跑的demo移到了m4的mcu,另一个项目是用高云fpga做了ov2640的串并转换到mcu处理,练习了fpga。5月份之前飞卡的软件队友提出来要再参加一次,让我做一下硬件,这次我非常熟练,PCB最多就设计了两版就完成了硬件设计;
大三暑假
暑假去了一家做半导体芯片的公司实习,是属于系统集成部,公司平均年龄比较大,部门里同事都不怎么说话,公司氛围不太好,领导经常会骂别人很凶,我一看不对劲就溜溜球了。暑假在做wifi图传的项目,尝试用m4自己看数据手册写WiFi驱动,不过后来这事没成,换了esp32用idf开发。很早开始我就对网络感兴趣,可能未来也会多往这个方向发展;
大四上学期
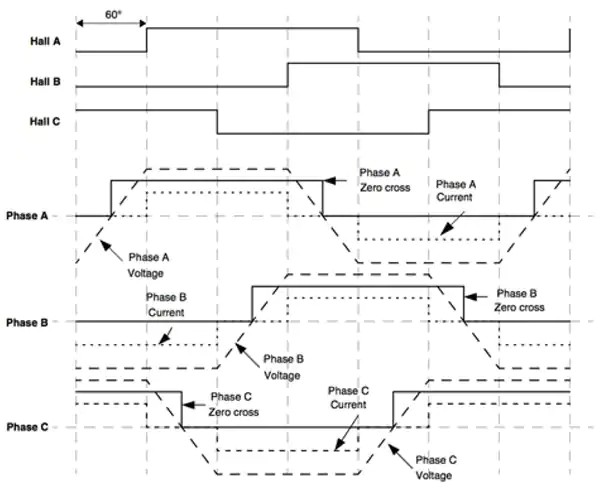
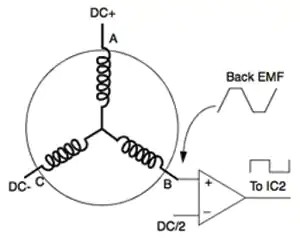
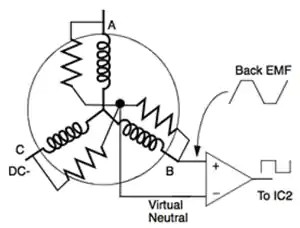
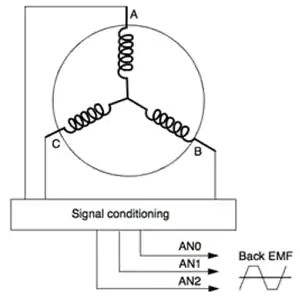
大四第一学期在世界五百强博世上班,公司的氛围特别好,领导都很有管理的能力,同事之间办公都非常的舒心,博世是个不加班的外企,但是工作效率挺高的,流程虽多,但处理速度很快。我在博世工作了4个月,学习了高压交流的PCB设计,直流无刷电机,永磁同步电机,把电力这一块学了一遍,也了解了电机的控制算法,最简单的六步换向,还有FOC。可以说这次实习经历相当难忘,每个牛的公司,都有一群好的团队管理者。这学期,还报名考研了,算是把大学的知识复习了一下,没考好,以后也不会再有考研的想法了;
还有最后一个假期
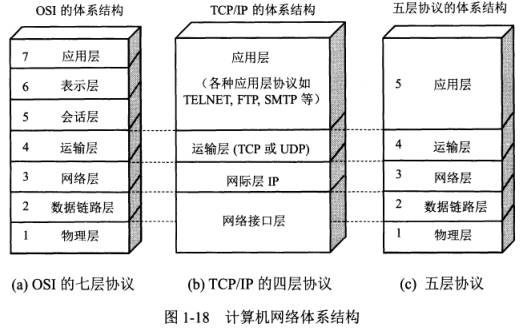
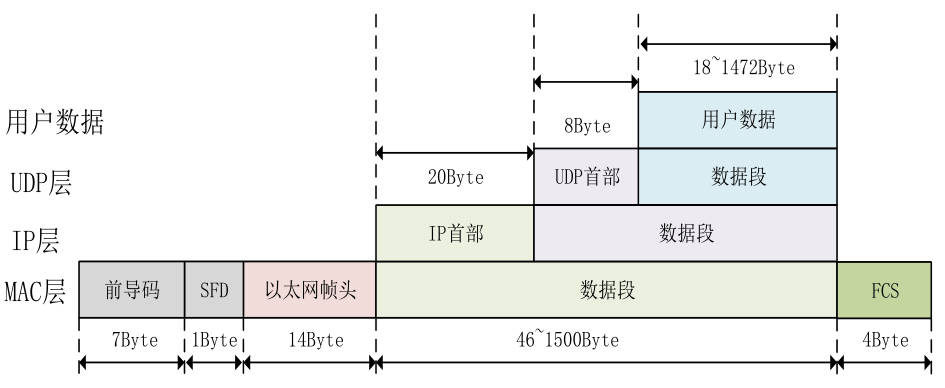
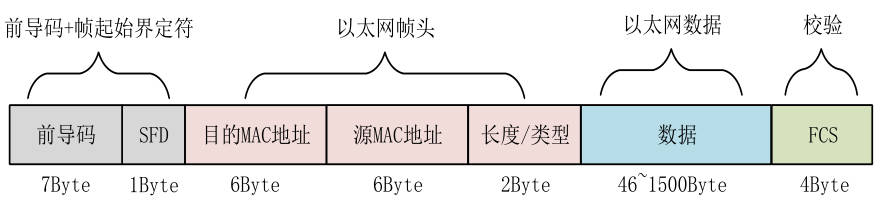
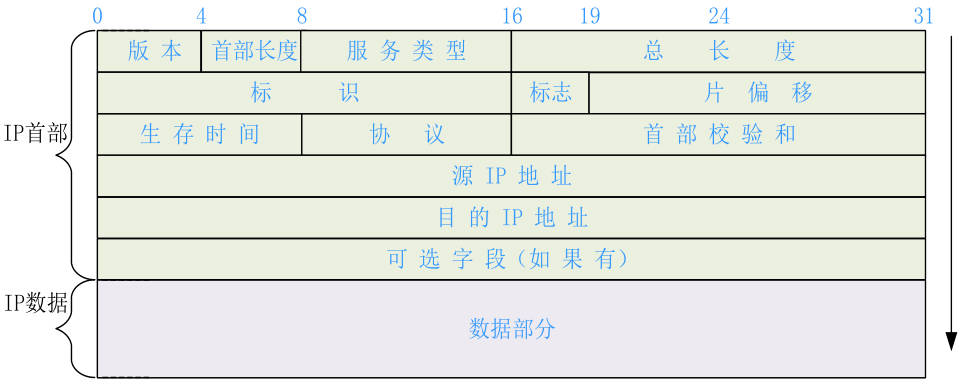
最后一个假期也没选择安逸,找了家做安防的公司实习,在这里我学到了linux驱动开发的知识,我的主管年龄挺大的技术很好,整个框架是他从头写出来的,我看git log一步步看他怎么写出来,太强了!面试的时候就被他的技术所吸引,这么强的人为人还非常谦虚,值得我去学习!在这里我重学了一年前了解过的makefile编写,shell脚本编程,C代码规范等等。看了主管写的几万行脚本代码,我再感叹到太强了!过年在家里自己系统的学了一遍计算机网络,本来还想学计算机组成原理和操作系统的,学操作系统的时候卡住了,看早期的linux源码也非常的费劲,只能推到我2月实习完回学校再学了;